
티스토리 뷰
[쿠버네티스 쉽게 이해하기 12] 헬스 체크를 위한 스타트업 프로브, 라이브니스 프로브, 레디니스 프로브
Happy@Cloud 2022. 5. 22. 20:3912. 헬스 체크를 위한 스타트업 프로브, 라이브니스 프로브, 레디니스 프로브
어플리케이션을 운영 할때 가장 운영자를 괴롭히는것 중 하나가 HTTP Hang현상입니다.
어플리케이션을 실행 시키는 물리적인 서버나 WAS는 정상인데 DB락, CPU 사용량 초과, 메모리 과다 사용 등의 이유로 어플리케이션의 응답 속도가 현저히 떨어지는 경우가 종종 있습니다.
문제는 그걸 체크 하기도 어렵고 현상이 벌어진 후에 원인을 찾아 조치하는데 시간이 너무 많이 걸린다는 겁니다.
쿠버네티스는 이 문제를 깔끔하게 해결하는 방법을 제공 합니다.
이번 장에서는 쿠버네티스가 서비스 정상 여부를 체크하고 조치하는 방법에 대해 배웁니다.
먼저 이러한 헬스 체크를 위한 라이브니스 프로브Liveness Probe, 레디니스 프로브Readiness Probe, 스타트업 프로브Startup Probe가 무엇인지와 어떻게 정의하는 지를 설명 하겠습니다.
그리고 위 세가지의 헬스 체크를 Command, HTTP, TCP로 하는 방법을 실습을 통해 이해하도록 하겠습니다.
마지막으로 문제가 있을 때 파드를 종료하는 시간을 단축시키는 방법에 대해 배워 보겠습니다.
<팁>
프로브Probe라는 단어는 ‘조사하다’라는 동사와 ‘조사'라는 명사입니다.
파드의 상태를 조사한다는 뜻으로 프로브라는 단어를 사용 합니다.
</>
12.1 라이브니스 프로브, 레디니스 프로브, 스타트업 프로브 이해와 정의 방법
쿠버네티스에서 헬스 체크를 위해 사용하는 세가지 체크 방법인 라이브니스 프로브, 레디니스 프로브, 스타트업 프로브가 무엇인지와 어떤 차이가 있는지를 알아 보겠습니다.
그리고 각 프로브를 야믈로 정의하는 방법에 대해 설명 하겠습니다.
1) 헬스 체크 방법 이해
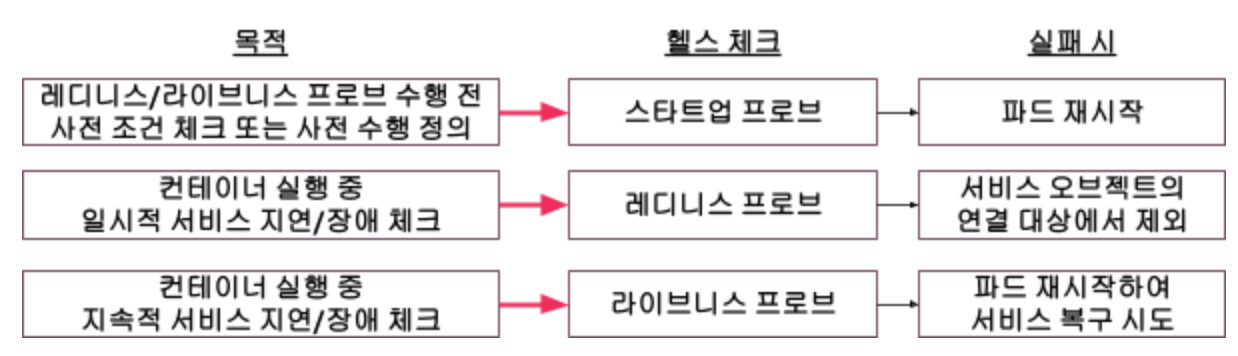
스타트업 프로브는 컨테이너 실행 전의 사전 조건 체크나 사전 수행을 정의할 수 있습니다.
스타트업 프로브가 성공하기 전까지 레디니스 프로브와 라이브니스 프로브는 시작되지 않습니다.
레디니스 프로브는 컨테이너가 실행된 후에 일시적인 서비스의 지연이나 장애 시 잠시 서비스를 쉬게 하는 목적으로 사용합니다.
라이브니스 프로브는 더 이상 서비스를 제공하기 힘든 상태인지를 체크하기 위해 사용 됩니다.
스타트업 프로브에 실패 하면 파드는 다시 시작 됩니다.
레디니스 프로브에 실패 하면 서비스는 잠시 중단 되었다가 레디니스 프로브에 정의한 수행이 성공하면 다시 서비스를 시작 합니다.
라이브니스 프로브에 실패 하면 파드를 재시작 하여 서비스를 정상화 시킵니다.
레디니스 프로브를 파드 시작할 때 사전 작업이 완료 되었는지 체크하는 목적으로 사용하는 것은 올바른 사용법이 아닙니다. 그 목적으로는 스타트업 프로브를 사용하는게 맞습니다.
예를 들어 아래와 같은 활용 시나리오를 만들 수 있습니다.
- 컨테이너 실행 전에 대량의 데이터를 마이그레이션 해야 한다면 그 작업이 끝날때까지 파드 연결을 하지 않게 스타트업 프로브에서 체크 합니다.
- 레디니스 프로브를 이용하여 특정 주소를 호출 했을 때 3초 이상의 응답이 3번 있으면 일시적 장애로 판단하고 서비스를 격리 시킵니다. 응답 시간이 3초 내로 돌아 오면 다시 서비스가 시작 됩니다.
- 라이브니스 프로브를 이용하여 특정 주소를 호출 했을때 10초 이상의 응답이 2번 발생 한다면 회복할 수 없는 장애로 판단하고 그 파드를 재 시작 합니다.
2) 정의 방법
헬스 체크를 위해서는 커맨드, HTTP Request, TCP를 사용할 수 있습니다.
커맨드는 리눅스의 명령어를 이용하는 방식이고 HTTP Request는 컨테이너 안의 웹 주소를 호출하는 방식이며 TCP는 컨테이너 포트로 접속을 체크하는 방법입니다.
프로브 명세는 컨테이너의 상태를 체크하는 것이므로 컨테이너 명세에 정의 합니다.
❶ 목적에 따라 스타트업 프로브, 레디니스 프로브, 라이브니스 프로브인지 지정 합니다.
❷ 헬스 체크의 방법에 따라 커맨드는 ‘exec’, HTTP Request는 ‘httpGet’, TCP는 ‘tcpSocket’ 항목 밑에 정의 합니다.
❸ 각 헬스 체크 방법의 상세한 설정을 여기에 지정 합니다.
❹ 헬스 체크의 파라미터를 정의 합니다.
- initialDelaySeconds: 최초 헬스 체크 시작 전에 기다리는 시간
- periodSeconds: 헬스 체크 시작 후 체크 주기
- timeoutSeconds: 응답 시간 제한
- failureThreshold: 몇 번까지 실패 시 최종 실패로 간주할 것인가 ?
- successThreshold: 몇 번까지 성공 시 최종 성공으로 간주할 것인가 ?
수행이 실패하거나 응답 시간 제한을 초과하면 실패로 간주 됩니다.

그럼 커맨드, HTTP Request, TCP로 헬스 체크하는 방법을 실습해 보겠습니다.
12.2 커맨드를 이용한 헬스 체크 실습
커맨드로 수행할 명령을 어떻게 정의하는 지 예제를 통해 설명 하겠습니다.
그리고 실제 예제 야믈을 배포하고 고의로 각 프로브를 실패 시켰을 때 어떻게 되는지 실습 하겠습니다.
실습 중에 쿠버네티스 대시보드를 이용하므로 대시보드를 로그인해 주십시오.
대시보드 로그인 방법은 ‘4.5 쿠버네티스 클러스터에 컨테이너 실행'을 참고 하십시오.
1) 커맨드로 프로브 정의 하기
커맨드로 헬스 체크를 정의할 때는 exec.command에 수행할 명령을 지정 하면 됩니다.
실습할 예제 야믈의 각 프로브는 아래와 같이 구성되어 있습니다.
스타트업 프로브에서 볼륨 마운트한 디렉토리의 파일을 찾고 ‘liveness’와 ‘readiness’라는 파일을 만듭니다.
수행할 커맨드가 여러줄인 경우는 아래와 같은 형태가 편합니다.
| … startupProbe: exec: command: - /bin/bash - -ec - | ls /home/docker/data/members.properties echo "I'm Live" > liveness echo "I'm Ready" > readiness |
<팁>
‘/bin/bash’는 리눅스 쉘 중 배시bash를 사용한다는 의미 입니다.
‘-ec’에서 ‘e’는 수행 중 에러가 나면 즉시 빠져 나가라는 의미이고 ‘c’는 뒤의 명령어를 실행하라는 파라미터 입니다.
</>
레디니스 프로브에서는 ‘readiness’ 파일의 내용을 보는 ‘cat’명령을 수행 합니다.
한 줄 명령일 때는 아래와 같이 대괄호로 정의할 수 있습니다.
| … readinessProbe: exec: command: [ "/bin/bash", "-ec", "cat readiness" ] |
라이브니스 프로브에서는 ‘liveness’ 파일의 내용을 보는 ‘cat’명령을 수행 합니다.
| … readinessProbe: exec: command: [ "/bin/bash", "-ec", "cat liveness" ] |
2) 실습 하기
배천노드에서 ‘~/k8s/yaml’로 이동 후 예제 야믈 파일을 다운로드 하십시오.
| [root@osboxes]# cd ~/k8s/yaml [root@osboxes yaml]# wget https://hiondal.github.io/k8s-yaml/3.12/probe-cmd.yaml |
야믈 파일을 이용하여 ‘probe-cmd’ 파드를 배포 하십시오.
정상적으로 잘 실행 될 겁니다.
| [root@osboxes yaml]# k apply -f probe-cmd.yaml [root@osboxes yaml]# k get po probe-cmd-0 NAME READY STATUS RESTARTS AGE probe-cmd-0 1/1 Running 0 149m |
스타트업 프로브의 수행을 실패하게 하여 어떻게 되는지 보겠습니다.
‘probe-cmd.yaml’파일을 열고 스타트업 프로브의 내용에서 ‘members.properties’를 다른 파일로 바꿉니다.
| … startupProbe: exec: command: - /bin/bash - -ec - | ls /home/docker/data/members.properties.test echo "I'm Live" > liveness echo "I'm Ready" > readiness |
다시 파드를 배포하고 어떻게 되는지 확인 합니다. ‘-w’옵션을 붙여 진행상황을 모니터링 합니다.
아래와 같이 파드가 실행되지 못하고 계속 재시작 할 겁니다.
| [root@osboxes yaml]# k apply -f probe-cmd.yaml [root@osboxes yaml]# k get po probe-cmd-0 -w NAME READY STATUS RESTARTS AGE … probe-cmd-0 0/1 Running 0 2s probe-cmd-0 0/1 Running 1 (<invalid> ago) 27s probe-cmd-0 0/1 Running 2 (<invalid> ago) 51s probe-cmd-0 0/1 Running 3 (<invalid> ago) 75s probe-cmd-0 0/1 Running 4 (<invalid> ago) 100s probe-cmd-0 0/1 CrashLoopBackOff 4 (<invalid> ago) 2m4s … |
스타트업 프로브의 옵션을 보면 아래와 같이 되어 있습니다.
“최초 헬스 체크는 3초 기다렸다가 실행되고 3초 마다 체크하며 수행 실패가 1번 이상이면 최종 실패로 간주한다.”
| … failureThreshold: 1 initialDelaySeconds: 3 periodSeconds: 3 successThreshold: 1 timeoutSeconds: 3 terminationGracePeriodSeconds: 5 |
대시보드에서 파드 ‘probe-cmd-0’의 이벤트를 보면 스타트업 프로브가 실패하자 컨테이너를 재 시작하는 것을 볼 수 있습니다.

이번에는 레디니스 프로브를 강제로 실패 시켜 보겠습니다.
스타트업 프로브는 원래대로 돌려 놓으시고 파드를 다시 시작하십시오.
레디니스 프로브는 ‘readiness’파일의 내용을 읽는 수행이고 옵션은 아래와 같습니다.
“최초 헬스 체크는 3초 기다렸다가 실행되고 3초 마다 체크하며 수행 실패가 10번 이상이면 최종 실패로 간주한다.”
| … readinessProbe: exec: command: [ "/bin/bash", "-ec", "cat readiness" ] failureThreshold: 10 initialDelaySeconds: 3 periodSeconds: 3 successThreshold: 5 timeoutSeconds: 1 |
파드가 정상 실행된 것을 확인하고 아래 명령으로 ‘readiness’파일을 강제로 지우십시오.
그리고 파드의 상태를 모니터링 하십시오.
대시보드에서 레디니스 프로브의 실패 횟수가 10회 이상이 되면 아래와 같이 ‘READY’가 ‘0/1’으로 바뀌는 걸 보실 수 있을 겁니다.
이와 같이 레디니스 프로브는 실패 시 이 파드로 트래픽이 들어오지 않게 서비스를 격리 시킵니다.
| [root@osboxes yaml]# k exec -it probe-cmd-0 -- rm readiness [root@osboxes yaml]# k get po probe-cmd-0 -w NAME READY STATUS RESTARTS AGE probe-cmd-0 1/1 Running 0 3m53s probe-cmd-0 0/1 Running 0 3m58s |
아래 명령으로 다시 레디니스 프로브를 성공 시켜 보십시오.
역시 파드의 상태를 모니터링 하십시오. ‘successThreshold’가 ‘5’이므로 조금 후 정상 실행 상태로 돌아 올 겁니다.
| [root@osboxes yaml]# k exec -it probe-cmd-0 -- touch readiness [root@osboxes yaml]# k get po probe-cmd-0 -w NAME READY STATUS RESTARTS AGE probe-cmd-0 0/1 Running 0 69s probe-cmd-0 1/1 Running 0 79s |
마지막으로 라이브니스 프로브를 테스트 해 보겠습니다.
라이브니스 프로브는 ‘liveness’파일의 내용을 읽는 수행이고 옵션은 아래와 같습니다.
“최초 헬스 체크는 1초 기다렸다가 실행되고 3초 마다 체크하며 수행 실패가 10번 이상이면 최종 실패로 간주한다.”
| … livenessProbe: exec: command: [ "/bin/bash", "-ec", "cat liveness" ] failureThreshold: 10 initialDelaySeconds: 1 periodSeconds: 3 successThreshold: 1 timeoutSeconds: 1 terminationGracePeriodSeconds: 5 |
파드가 정상 실행된 것을 확인하고 아래 명령으로 ‘liveness’파일을 강제로 지우십시오.
그리고 파드의 상태를 모니터링 하십시오.
대시보드에서 라이브니스 프로브의 실패 횟수가 10회 이상이 되면 아래와 같이 ‘RESTART’가 1로 바뀌는 걸 보실 수 있을 겁니다.
파드가 다시 시작 하면서 스타트업 프로브에서 ‘liveness’파일을 다시 생성하므로 라이브니스 프로브는 성공하게 됩니다.
이와 같이 라이브니스 프로브는 실패 시 파드를 재시작하여 서비스를 정상화 시킵니다.
| [root@osboxes yaml]# k exec -it probe-cmd-0 -- rm liveness [root@osboxes yaml]# k get po probe-cmd-0 -w NAME READY STATUS RESTARTS AGE probe-cmd-0 1/1 Running 0 7m35s probe-cmd-0 0/1 Running 1 (<invalid> ago) 8m22s probe-cmd-0 0/1 Running 1 (<invalid> ago) 8m25s probe-cmd-0 1/1 Running 1 (<invalid> ago) 8m25s |
12.3 HTTP Request를 이용한 헬스 체크 실습
웹 기반의 어플리케이션은 HTTP Request를 이용하여 헬스 체크를 하는게 서비스가 정상적인지 체크하는 가장 확실한 방법입니다.
특히 컨테이너가 시작되고 서비스를 할 준비가 될 때까지 수분 이상이 걸리는 경우 스타트업 프로브로 체크 안 하면 아직 준비가 안된 파드와 연결되어 에러가 납니다.
HTTP Request를 어떻게 정의하는지부터 설명하고 실제 예제를 통하여 실습 하겠습니다.
리소스가 부족할 수 있으니 먼저 기존의 오브젝트들을 정리 하겠습니다.
| [root@osboxes yaml]# k delete sts --all [root@osboxes yaml]# k delete deploy --all [root@osboxes yaml]# k delete svc --all [root@osboxes yaml]# k delete ing --all [root@osboxes yaml]# k delete cm --all [root@osboxes yaml]# k delete secret --all [root@osboxes yaml]# k delete pvc --all [root@osboxes yaml]# k delete pv --all |
<팁>
리소스 유형별로 한꺼번에 오브젝트들을 삭제할 때는 ‘--all’ 파라미터를 이용 하십시오.
</>
1) HTTP Request로 프로브 정의 하기
HTTP Request로 헬스 체크를 정의할 때는 httpGet 항목 아래에 아래와 같이 지정 합니다.
- scheme: 통신 프로토콜을 정의합니다. HTTP 또는 HTTPS로 지정할 수 있고 생략 시 HTTP입니다.
- host: 컨테이너의 Host명이며 기본 값은 파드 IP입니다. 보통 생략 합니다.
- port: 컨테이너가 수신하고 있는 포트번호를 지정 합니다. 번호를 지정할 수도 있고 ‘ports’에 정의한 포트명을 사용할 수도 있습니다.
- path: 호출할 주소를 지정 합니다.
- httpHeaders: 호출 시 HTTP Header값을 지정 합니다. name과 value를 복수로 지정할 수 있습니다.
특별한 이유가 없다면 path와 port로 충분 합니다.
| … ports: - name: containerport containerPort: 3001 … livenessProbe: httpGet: port: containerport path: /actuator/health httpHeaders: - name: Host value: probe-httpreq initialDelaySeconds: 30 periodSeconds: 5 timeoutSeconds: 10 failureThreshold: 3 successThreshold: 1 |
2) 실습하기
실습에 사용되는 어플리케이션은 ‘member’ 서비스 입니다.
스프링 부트 액추에이터Actuator 라이브러리가 제공하는 헬스 체크 주소인 ‘/actuator/health’를 사용하여 체크 합니다.
샘플 야믈인 ‘probe-httpreq.yaml’파일을 다운로드 합니다.
| [root@osboxes yaml]# wget https://hiondal.github.io/k8s-yaml/3.12/probe-httpreq.yaml |
인그레스의 host 값 중간에 있는 IP를 본인 노드의 IP로 변경 하십시오.
| apiVersion: networking.k8s.io/v1 kind: Ingress … spec: rules: - host: probe-httreq.169.56.70.201.nip.io … |
이 어플리케이션은 컨테이너 시작 후 서비스가 준비 될 때까지 수분 이상이 걸립니다.
그래서 스타트업 프로브로 서비스가 준비될 때까지는 서비스 오브젝트가 연결 하지 않도록 합니다.
옵션을 아래와 같이 지정하여 충분한 시작 시간을 보장 합니다.
“최초 헬스 체크는 60초 기다렸다가 실행되고 10초 마다 체크하며 수행 실패가 30번 이상이면 최종 실패로 간주한다.”
| … startupProbe: httpGet: port: containerport path: /actuator/health httpHeaders: - name: Host value: probe-httpreq initialDelaySeconds: 60 periodSeconds: 10 timeoutSeconds: 2 failureThreshold: 30 successThreshold: 1 |
레디니스 프로브도 동일한 주소로 체크 합니다.
단 옵션을 아래와 같이 지정하여 일시적인 서비스 장애인지를 판별 합니다.
“최초 헬스 체크는 10초 기다렸다가 실행되고 5초 마다 체크하며 응답시간 3초 이상이 5번 이상이면 최종 실패로 간주한다.”
| … readinessProbe: httpGet: port: containerport path: /actuator/health initialDelaySeconds: 10 periodSeconds: 5 timeoutSeconds: 3 failureThreshold: 5 successThreshold: 1 |
라이브니스 프로브 역시 동일한 주소로 체크하지만 타임아웃을 길게 줘서 비정상적인 장애인지를 판별 합니다.
“최초 헬스 체크는 10초 기다렸다가 실행되고 5초 마다 체크하며 응답시간 10초 이상이 3번 이상이면 최종 실패로 간주한다.”
| … livenessProbe: httpGet: port: containerport path: /actuator/health initialDelaySeconds: 30 periodSeconds: 5 timeoutSeconds: 10 failureThreshold: 3 successThreshold: 1 |
실습은 새로운 버전 배포 시 무중단 서비스를 제공하는 것을 체험하기 위해 아래와 같은 순서로 진행 합니다.
- 파드와 관련 오브젝트인 퍼시스턴트 볼륨, 퍼시스턴트 볼륨 클레임, 서비스, 인그레스를 배포함
- 새 버전 배포를 위해 컨테이너 이미지 교체
- 기존 파드가 하나씩 사라지고 새로운 파드가 생성되며 스타트업 프로브로 인해 장애 없는 서비스가 제공됨을 확인
‘probe-httpreq.yaml’을 이용하여 오브젝트들을 배포 합니다.
파드가 시작되는 것을 모니터링 합니다.
| [root@osboxes yaml]# k apply -f probe-httpreq.yaml [root@osboxes yaml]# watch k get po |
또한 대시보드에서도 계속해서 스타트업 프로브가 실패 나다가 어느 순간 더 이상 실패가 안나는것도 확인 합니다.

다른 터미널 탭을 열고 파드의 로그도 확인해 봅니다. ‘/actuator’ 주소가 노출되면 더 이상 스타트업 프로브가 실패하지 않고 서비스 준비 상태가 됩니다.
| [root@osboxes yaml]# k logs -f probe-httpreq-0 . ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.6.2) 2022-01-31 14:45:05.037 INFO 7 --- [ main] com.ott.member.MemberApplication : Starting MemberApplication v0.0.1-SNAPSHOT using Java 11.0.13 on probe-httpreq-0 with PID 7 (/home/docker/member.jar started by docker in /home/docker) … 2022-01-31 14:46:03.645 INFO 7 --- [ main] o.s.b.a.e.web.EndpointLinksResolver : Exposing 1 endpoint(s) beneath base path '/actuator' … |
이제 새로운 버전의 컨테이너 이미지를 배포 합니다.
아래 명령으로 컨테이너 이미지를 교체 합니다.
기존 파드가 하나씩 사라지고 새로운 파드가 생성 됩니다.
| [root@osboxes yaml]# k set image sts probe-httpreq probe-httpreq=docker.io/hiondal/member:latest statefulset.apps/probe-httpreq image updated [root@osboxes yaml]# watch k get po NAME READY STATUS RESTARTS AGE curl 1/1 Running 1 (12d ago) 12d probe-httpreq-0 1/1 Running 0 7m33s probe-httpreq-1 1/1 Running 0 7m33s probe-httpreq-2 0/1 Running 0 49s |
웹브라우저를 열고 인그레스 주소로 API 주소를 접근 합니다.
계속 리프레시 해 보십시오. 준비가 된 파드로만 접근 되어 에러 없이 계속 서비스가 됩니다.
http://{인그레스 주소}/members/user1
12.4 TCP를 이용한 헬스 체크 실습
TCP포트를 이용하여 컨테이너 포트로 접속이 되는지를 체크하는 방법입니다.
TCP를 어떻게 정의하는지부터 설명하고 실제 예제를 통하여 실습 하겠습니다.
1) TCP로 프로브 정의 하기
TCP로 헬스 체크를 정의할 때는 tcpSocket 항목 아래에 ‘port’에 컨테이너 포트 번호나 컨테이너 포트 이름을 지정 하면 됩니다.
| … ports: - name: containerport containerPort: 8080 … livenessProbe: tcpSocket: port: containerport initialDelaySeconds: 10 periodSeconds: 3 timeoutSeconds: 1 failureThreshold: 10 successThreshold: 1 |
2) 실습하기
샘플 야믈인 ‘probe-tcp.yaml’파일을 다운로드 합니다.
| [root@osboxes yaml]# wget https://hiondal.github.io/k8s-yaml/3.12/probe-tcp.yaml |
파일을 열어 TCP를 사용하여 스타트업 프로브, 레디니스 프로브, 라이브니스 프로브를 어떻게 정의 했는지 확인 하십시오.
파드를 배포하여 정상적으로 파드가 실행 되는지 확인 하십시오.
| [root@osboxes yaml]# k apply -f probe-tcp.yaml [root@osboxes yaml]# watch k get po probe-tcp-0 NAME READY STATUS RESTARTS AGE probe-tcp-0 1/1 Running 0 15s |
12.5 문제 발생 파드의 신속한 종료 방법
스타트업 프로브나 라이브니스 프로브가 최종적으로 실패하면 파드를 자동으로 재 시작 합니다.
파드를 재시작하기 위해 기존 파드를 삭제할 때는 안전한 종료를 위해 일정 시간이 필요 합니다.
그 시간을 보장해 주는 방법이 ‘terminationGracePeriodSeconds’이며 기본 시간은 30초 입니다.
그런데 스타트업 프로브나 라이브니스 프로브의 실패 시에는 좀 더 빨리 파드를 종료해도 되기 때문에 이 시간을 줄일 수 있어야 합니다.
그래서 쿠버네티스는 스타트업 프로브나 라이브니스 프로브를 정의할 때 옵션으로 ‘terminationGracePeriodSeconds’를 재정의할 수 있도록 합니다.
예제로 실습 했던 세개 야믈 모두에는 아래와 같이 스타트업 프로브와 라이브니스 프로브에서 이 종료 시간을 재정의하고 있습니다.
아래 예제는 스타트업 프로브와 라이브니스 프로브 실패시 파드의 종료 시간은 5초로 하고 그 외의 이유로 종료될때는 20초로 한다는 것입니다.
| … spec: … template: … spec: containers: - name: probe-cmd image: hiondal/hello imagePullPolicy: IfNotPresent startupProbe: … terminationGracePeriodSeconds: 5 readinessProbe: … livenessProbe: … terminationGracePeriodSeconds: 5 … terminationGracePeriodSeconds: 20 |
쿠버네티스 쉽게 이해하기 시리즈 목차
[쿠버네티스 쉽게 이해하기 1] 쿠버네티스 설치하기
[쿠버네티스 쉽게 이해하기 2] 쿠버네티스 아키텍처
[쿠버네티스 쉽게 이해하기 3] 한장으로 이해하는 쿠버네티스 리소스
[쿠버네티스 쉽게 이해하기 4] 쿠버네티스 개발에서 배포까지 실습
[쿠버네티스 쉽게 이해하기 5] 쿠버네티스 오브젝트 정의 파일 쉽게 만들기
[쿠버네티스 쉽게 이해하기 6] 꼭 알아야 할 쿠버네티스 주요 명령어
[쿠버네티스 쉽게 이해하기 7] 파드 실행 및 통제를 위한 워크로드 컨트롤러
[쿠버네티스 쉽게 이해하기 8] 파드 로드 밸런서 서비스
[쿠버네티스 쉽게 이해하기 9] 서비스 로드 밸런서 인그레스
[쿠버네티스 쉽게 이해하기 10] 환경변수 컨피그맵과 시크릿
[쿠버네티스 쉽게 이해하기 11] 데이터 저장소 사용을 위한 PV/PVC
[쿠버네티스 쉽게 이해하기 12] 헬스 체크를 위한 스타트업 프로브, 라이브니스 프로브, 레디니스 프로브
[쿠버네티스 쉽게 이해하기 13] 통합 로깅을 위한 EFK 스택
[쿠버네티스 쉽게 이해하기 14] 인증Authentication과 알백RBAC 방식의 인가Authorization
[쿠버네티스 쉽게 이해하기 15] 더 알면 좋을 주제들: 무중단 배포, 모니터링, HPA
'Cloud > Kubernetes' 카테고리의 다른 글
| [쿠버네티스 쉽게 이해하기 14] 인증Authentication과 알백RBAC 방식의 인가Authorization (2) | 2022.05.22 |
|---|---|
| [쿠버네티스 쉽게 이해하기 13] 통합 로깅을 위한 EFK 스택 (0) | 2022.05.22 |
| [쿠버네티스 쉽게 이해하기 11] 데이터 저장소 사용을 위한 PV/PVC (1) | 2022.05.22 |
| [쿠버네티스 쉽게 이해하기 10] 환경변수 컨피그맵과 시크릿 (0) | 2022.05.22 |
| [쿠버네티스 쉽게 이해하기 9] 서비스 로드 밸런서 인그레스 (0) | 2022.05.22 |
- Total
- Today
- Yesterday
- 요즘남편 없던아빠
- 분초사회
- 애자일
- 도파밍
- spotify
- AXON
- API Composition
- agile
- 리퀴드폴리탄
- 마이크로서비스
- 육각형인간
- Event Sourcing
- micro service
- 스핀프로젝트
- 호모프롬프트
- SAGA
- 마이크로서비스 패턴
- 스포티파이
- CQRS
- 디토소비
- 돌봄경제
- 버라이어티가격
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |